 For the past two decades, I have been consumed with positive impact. How do I leave the world better? How do I do great things that help? How do I help teams do great things that help? When I started my career, the focus was on how my individual contributions could produce this change. As time progressed and my responsibilities increased, the focus moved to how I could create an environment for my team(s) to do their best work. Years in the trenches - working, managing, leading, coaching, mentoring, reading, applying, learning and incorporating lessons - have surfaced four principles that are common to the highest-producing, highest-functioning teams that I have been a part of. Trust Lack of trust between team members is a solid indicator that your team, company or agency will be operating from a place of fear, will be high stress, will contain lots of isolated teams and people, will have high turnover and will not be performing as efficiently as it should be. A “high trust” environment is fundamental and a critical building block for a great team. This environment provides a team with the psychological safety that is needed to create a high-performance, high-retention, collaborative and productive space. For leaders who want to create a team with high trust as its core, the strategy must include: 1) ensuring that relationship building is a natural, everyday part of people’s work life; 2) enforcing equal airtime for team members during meetings; 3) emphasizing that every team member should assume good intent for each action they observe or experience; and 4) encouraging the vocalizing, vetting and supporting of all the ideas brought forward by team members. From my experience, taking these steps will normally create a more cohesive, happier, more loyal and more fulfilled team. Productivity normally increases, turnover decreases and teamwork strengthens. Truth The more dominant (and popular) management techniques that I have seen being commonly used by leaders tend to emphasize the chain of command, information layers and the filtering of context and data about projects and goals down the chain. Unfortunately, this creates an environment where team members are operating with half truths and missing information. For successful execution of your team’s mission, this raises a set of interesting problems that actively work against the team being successful. A “high truth” environment is built on transparency, realistic expectation setting, facilitating and having difficult conversations and giving and receiving constructive criticism well. A team member who knows the reality of the mission, the project, how the project contributes to the mission, the actual constraints of the project and the actual business, legal, technical and social factors that shape the project will have a higher probability of making great decisions. This will also help with delivery that is on time, in scope, under budget and embraced by happy and satisfied customers. Unfortunately, the groundwork for leaders to build this environment involves dealing with messy human emotions and concepts that most of us are trained to avoid. Fortunately, the Harvard Business Journal has a cache of valuable publications that help you take the steps necessary. Empathy Empathy is the ability to see and understand a situation that you are involved with from the perspectives of the other people in the situation. My experience is that “high-empathy” colleagues normally lead to collaborations and customer products that are well-received, joyful and successful. Ever work with someone that rubs everyone on the team the wrong way? Ever have a teammate that only understands, advocates and pushes their perspective or agenda? Ever interact with a coworker that immediately defaults to an us-against-them mentally? If you have, then you had the pleasure of working with a “low empathy” individual. Generally, the best course of action for leaders is to hire for “high empathy.” If this is not possible and you have team members that need to evolve as human beings on the empathy front, then a leader has a lot of customized and individualized coaching and mentoring to perform with these colleagues. Clarity There is nothing worse than working for an organization with a vague mission, a vague vision and even vaguer project definitions. Though some flexibility is often necessary in software development projects, flexibility should and can be built into goals that are clear. Lack of clarity allows every level of management and every team member to interpret goals the way they want to. Given that everyone has their own unique story and journey means that there will be multiple viewpoints of what should get done and multiple people doing very different misaligned things. They might also claim that they are synergistically working towards the same outcome. Leaders can and should detect these misinterpretation issues and take measures to provide clarity and define reality using a common set of agreed-upon fundamentals around tasks and goals. The series of interactions that are necessary are also great ways to enable crucial relationship building that is necessary for high trust environments. Conclusion Over the last five years, Google’s quest to build a perfect team has codified and put formal names to the experiences I have had. Their study, available here, is a great read for someone who wants to go deeper. Building great teams that produce great work is difficult, but a necessity in today’s world. Through a series of failures and hard life lessons, I have seen the importance of trust, truth, empathy and clarity. I have used these concepts on each team that I have either created or been a part of, over the last decade, to great result. I hope would they help you. This post was also published on GovLoop.
1 Comment
 The year is 2020 and NASA's Planetary Defense Coordination Office (yes, it's real) has notified the world that an Extinction Level Event (ELE) - let's say a series of asteroids moving quickly on a collision course - is projected to wipe out the Earth in three months. What should our response strategy be? Do we:
Unfortunately, neither Options 1 or 2 get you to a level of understanding of the root cause of the issue and instead of solving the problem, you most likely end up addressing a symptom. 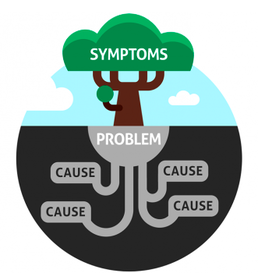 For Option 1, the possibility exists that the asteroids you destroy are a sign of things to come and that there are bigger, faster, weird-behaving masses right behind them. So, taking this approach may only buy us time. For Option 2, because there are no early detection systems on this new planet, we could be buying a few more months (as other asteroids are barreling towards this new planet), we could be getting humanity out of harm's way, or we may be putting the human race in a worst situation (if there are structural issues that make the new planet a ticking time bomb). Option 3 - determining the root cause of the situation - requires calm, focused, objectivity on the What, Why? Where? Who? When? and How? Filling out the scenario with this information not only guides us to the correct path to take, but helps lessen the chances of unforeseen and unexpected subsequent issues. It is well-known insight in computer science that formulating the problem correctly is far more valuable than rushing to a solution based on surface facts about the customer's pain points. However, it has become obvious that far too few people spend time trying to determine the root cause of a problem. Over the past month, I have been reading an increasing number of articles promoting solutions to issues that simply put a controlled solution box around a symptom, rather than solve the real problem. Let's take two areas: the refugee crisis and the diversity crisis in tech. Refugee Crisis Here is the existing narrative with regards to the Refugee Crisis: Global migration has reached an unprecedented scale. Millions of people cross borders every year in search of new opportunities, carrying with them enormous potential to contribute to economic development, address demographic challenges, and foster global interconnectedness. But global migration also comes with pressing challenges. Many migrants undertake perilous journeys only to be exploited or face deportation. Women and children are illegally trafficked across international borders and sold into slavery. Even legal migrants are facing a rising tide of xenophobic backlash. Global refugee numbers are continuously rising as civil wars and conflicts rage on. Climate disasters and changing environment will further cause the displacement of hundreds of thousands of people. The current approaches to solving this issue revolves around answering the following questions:
But what is the root cause of this crisis? Political unrest, civil war, and gentrification stem from unbalanced and unjust economic models and incentive schemes that promote discord, strife and conflict at the micro level in service of (personal) profitability for a select few at the macro level. This inequality and the inability of a few to empathize with others and view them as a part of their family drives the conditions that produce environments where the weak and powerless have to flee; in hopes of increased safety and the possibility of better opportunities. Much of this knowledge and nuance is hidden from most. Much of this activity is (covertly) performed by the elected representatives and wealthy citizens of the countries that refugees migrate to. The public tends to be blissfully unaware. With this knowledge hidden, the general populous is provided with a narrative that paints a picture of a distant problem, in a distant land, involving “others” and completely divorced from themselves, leading to an influx of people that want to drain their resources, take what is theirs, and erode their quality of life and their way of living. The critical first steps in solving this is with education, increased awareness, and empowerment. Educating powerful stakeholders that there are fruitful and lucrative alternatives, which are better for everyone in the long run. Educating the general public on their role, whether knowingly or unknowingly, in creating these crises. Educating the residents of the country that refugees are migrating to on empathy, on the benefits of immigrants, and on demystifying the fears and myths that they hold. Educating the world that addressing the refugee crisis is about more than crafting solutions around the consequences of the problem, but rather creating fundamental and positive changes that address the sources of the issue. Diversity in Tech Sad to say that since I wrote this piece in June of 2015, it is still relevant and the majority of people don't seem to get it - systemic racism is the root cause for the lack of diversity in computer science. Apple's diversity number haven't changed (more here). Companies are still holding talking sessions between white male and white female leaders on Diversity in Tech (more here). The narrative of it being bigger than race, that we should take incremental steps, and start with white women first is still being pushed (more here, here, here, and here). Accelerators, social entrepreneurs, and social venture capitalists are still being heralded as "the path" forward (more here and here). It appears that it is too difficult for people to be thoughtful, introspective, and to objectively name the root cause - a system built to ensure that one community succeeds at all costs and at the detriment of all other communities. The system needs to be changed to be fair and equitable for all, and its "in-power" community members need to re-socialized. Without this crucial first step, we are putting bandaids on the symptoms and not fixing the root cause. We can create solution layers on top, but still won't stop managers from discriminating and hiding it. These symptom solutions will only lead to new and interesting manifestations of the root cause. Please re-read "Real Talk About Diversity in Tech" and be real with me and yourself as to the problems we need to be looking at. Where are you seeing people addressing the symptom and not the root cause (This post is also available on LinkedIn)
 I just tried to load the website for the Commerce Data Service (http://www.commerce.gov/dataservice) and it redirected to http://www.commerce.gov, which means that the Service is officially dead. I have no idea when it was officially shut down. However, the last snapshot from the Way Back Machine was on July 31st, 2017. It kinda hurt. I had a moment. The startup that Jeff Chen and I founded and poured 100+ hour weeks into is no more. Rather than be sad, it is time to celebrate. As a team, we ran fast and we ran far. We created a program to teach Commerce employees human-centered design, agile software development, and data science. A program that is now a model adopted and used by other Federal agencies. We worked side-by-side with Commerce agencies to deliver over twenty solutions that improve their efficiency and highlight a new way to engage with vendors, staff, and the American public. We helped to spotlight and engage the private sector and everyday Americans on the power of the data that Commerce collects and makes available for free -- addressing everything from income inequality, to access to opportunity, to the school-to-prison pipeline for minority girls and women, to intellectual property innovation. We moved the needle on getting the technical infrastructure of the Department more aligned to best practices in today's information economy. The world outside of Commerce saw the work & its impact and publicly recognized the team through numerous awards. It was the best of times. It was the worst of times. Mostly, it was a helluva time. Cheers, to the Commerce Data Service (CDS) team.  For more information on the CDS, see:
(This post is also available on LinkedIn)
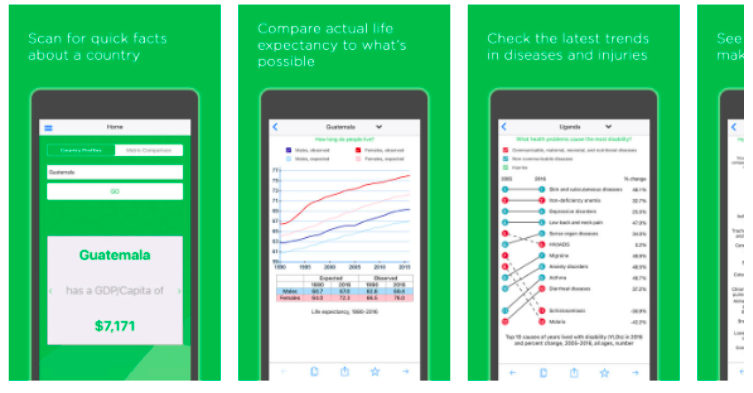 Today (September 25th, 2017), the Institute for Health Metrics and Evaluation (IHME) is pleased to release the Health Atlas mobile application (formally "Health Atlas by IHME") - a mobile app, available on Android and Apple devices, that provides country-level statistics from the Global Burden of Disease (GBD).  You can explore country-level stats on over 200 countries, compare trends for each country from 1990 to 2016, determine which diseases lead to the most loss of healthy life, share interesting findings with your friends and co-workers on social networks and other platforms, customize and filter the data displayed in each graph, easily copy and embed graphs into emails, texts, documents and presentations, and discover leading causes of death and injury by gender, age group, and geography.  You can currently access the app's data in English, Chinese, Spanish and Russian. If you have feedback or ideas for improvement, send your thoughts to [email protected]. More information is available at http://www.healthdata.org/healthatlas. (This post is also available on LinkedIn)
 At 3:30pm today (September 14th, 2017), the Institute for Health Metrics and Evaluation (IHME) launched the 2016 Global Burden of Disease (GBD) - a comprehensive data set on the risks, injuries and diseases that impact the number of healthy years due to various factors; across gender, age groups, and time. GBD Compare (https://vizhub.healthdata.org/gbd-compare/) now contains the data from the 2016 round of analysis. 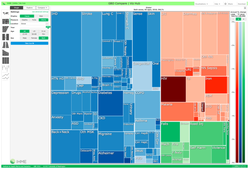 You can now analyze updated data about the world's health levels and trends from 1990 to 2016 in this interactive tool. Use treemaps, maps, arrow diagrams, and other charts to compare causes and risks within a country, compare countries within regions or the world, and explore patterns and trends by country, age, and gender. Drill from a global view into specific details. Compare expected and observed trends. Watch how disease patterns have changed over time. See which causes of death and disability are having more impact and which are waning. You can download the raw data, for non-commercial purposes, using the GBD Results Tool(http://ghdx.healthdata.org/gbd-results-tool). 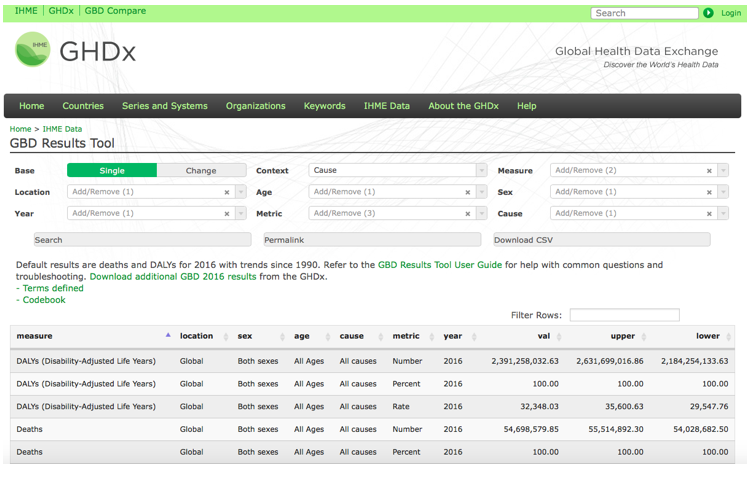 You can use the Data Sources Tool (http://ghdx.healthdata.org/gbd-2016/data-input-sources) to explore the input data used in creating the 2016 Global Burden of Disease. 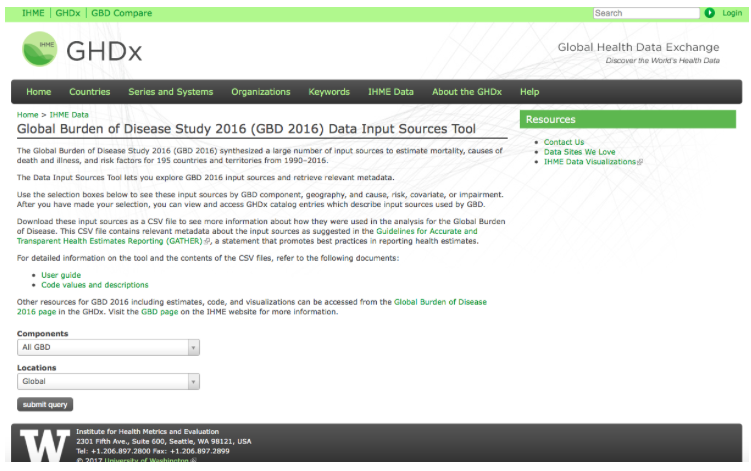 If you want to browse, reuse, or improve the code used in the production of the GBD, it is publicly available on Github (https://github.com/ihmeuw/ihme-modeling). 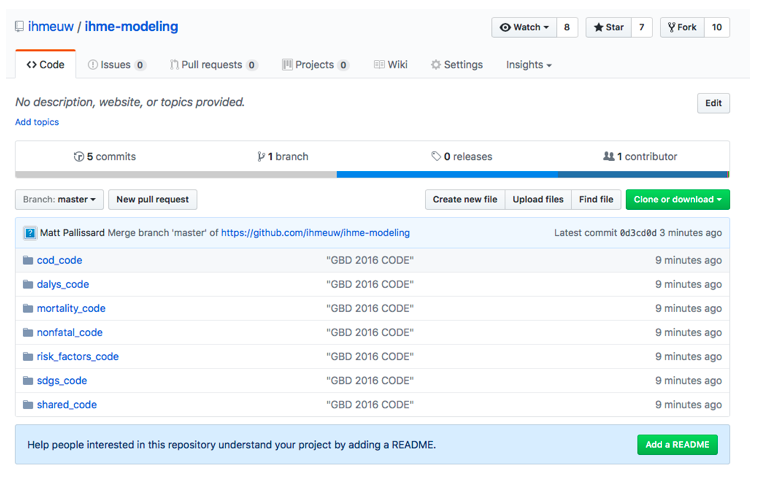 (This post is available on LinkedIn)
 Data is now widely recognized as the most important asset that any company, public sector or private entity, possesses. The latent power of data and recent technological advances, in the production and utilization of insight gained from extremely large volumes of varied, multi-modal and high-frequency data sets, has led to the recent rise of a new class of professional roles — Chief Data Officers, Chief Data Scientists, Chief Data Evangelists, Chief Data Strategists, etc. It has been about 5 years since these roles have become “hot jobs”. As someone who had the honor of being amongst the first wave of these professionals in the US Federal government and who achieved success in the role (read about my time as the Deputy Chief Data Officer for the US Department of Commerce here and see what we accomplished here), I want to share the lessons learned from my service. From my experiences, effectiveness as a Chief Data Executive hinges on three critical factors: Influence Current expectations are that a Chief Data Executive should be a technologist, a developer (scoping, implementing, and transitioning data products and services), a steward (for improving data quality), an evangelist (for data sharing and novel data business model generation), and a strategic visionary (for the organization’s data assets). It is impossible for a single person to be all these things and accomplish them all in any given work week. Thus, it becomes critically important that the Chief Data Executive is an excellent “manager by influence” — able to synergistically guide and work with other teams to execute on the data mission. This influence is the cornerstone of the collaborations necessary to achieve escape velocity and then have long-term success and sustainability. Integrity Building these alliances, which lead to a pathway of success, is built upon the trust that one’s colleagues must have in you with regards to your word, and with regards to your moral compass and values. A Chief Data Executive whose actions and or words are not grounded in integrity will have a hard time achieving and maintaining the relationships necessary for any sort of success. Competence In this context, competence refers to “having sufficient skill, knowledge, and experience to perform the job”, i.e. being properly qualified. The common set of skills that are required to be a Chief Data Executive include knowledge of the business and mission, knowledge of computer science, data science, or both, and knowledge of product definition and delivery. A competent Chief Data Executive is a rare mix of technical guru, businessperson, marketer, and adept executive leader — someone able to communicate in all spheres and that can easily translate between each. At this moment in time, many organizations and employees are still struggling to understand what Chief Data Executives do, where they fit into the organization, what their essential skills should be (based on their needs), what these executives are responsible for, who they should report into, and how to measure their impact. But these are all topics for another time. :-) (This post is also available on Medium)
At the 2016 IEEE 2nd International Conference on Collaboration and Internet Computing (CIC 2016) in Pittsburgh, Pennsylvania this November, Star Ying and I will present a paper on Big Data Privacy (read paper here). In this paper, we provide a simple description of something that should be obvious to most — there is no privacy when it comes to Big Data. In the paper we describe the “as-is” state of the data privacy protection practice, and model the core of what constitutes Big Data. We then weaved the two worlds together using a probabilistic framework and take the framework to its obvious, natural conclusion. This is the start of a critical discussion and introspection — one that we hope the community will engage in.  (This post is also available on LinkedIn)
As obvious as it sounds, the fact that different people have different histories and lived experiences, based on everything from the physical location where they grew up to the mentality of their parents and loved ones to the color of their skin, is an important and powerful one. The obvious implication is that there are truths that may not be known to some that are as plain to others as the freckle on one's nose. So, in an effort to share my experiences and shed some light on things that are obvious to me, I am starting a series of blogs called "Tales of the Obvious". The first formal installation in this series is about the Human Resources (or HR) Department of your current or past company.  Technically, Human Resource Management - the function of the HR department - is to maximize employee performance as it relates to the employer's strategic objectives. The HR department primarily uses policies and systems to optimize the management and output of people in the organization. Nowhere in the definition of the HR department's mission is there a focus on the well-being of the employee or acting on the employee's behalf. Yet, many employees assume that the HR department is their advocate when it comes to issues with the organization. Based on over two decades worth of experience interfacing with HR departments in corporate America, in academia, in the startup world, and in the Federal government, the only thing that I have found to be true about the HR department is that: The HR Department exists to 1) optimally align an organization's human capital with the efficient execution of its mission, and to 2) protect the organization's interests. Currently, any trust that an employee puts in the HR department with regards to the HR department fairly representing them before the organization's leadership is often mis-placed and mis-guided. I have heard five stories from my friends over the last three days. Though these interactions are not representative of the employed population of the world, I was shocked each time I heard a friend say that they expected HR to look out for their interests, when it went counter to what was good for the business and its leadership.
Social Experiment: Don't take my word for it, ask your friends about their difficult HR experiences and how they ended up. More importantly, this truth leads to an opportunity and a growing need. The field of Human Resource Management is perfectly positioned to go through a renaissance and evolve into a field that is more inclusive - marrying impartial mediation, with employee advocacy and employer priorities. The time is right for Human Resource Management 2.0 or 3.0 - where empathy, compassionate and advocacy are cornerstones. What do you think? What other things are obvious to you that you think people around you are not fully aware of yet? Write your own blog about it and share it with me. The following is an excerpt of a lightning talk that I gave at the 2015 Socrata Customer Summit on October 27th, 2015.  The Cellphone!!!!! This is one of the modern miracles of the current age. It is one of the most pervasive and most cherished devices, EVER. Everyone has at least one. And a lot of people, even those that won’t publicly admit it, have separation anxiety when they are away from one. Just on this device, our ONE agency - the Department of Commerce - has had a huge influence. The material standards for manufacturing rely on standards from NIST - The National Institute of Standards and Technology. The Intellectual Property for the technology on this device is safeguarded by the USPTO - Patent and Trademark Office. Your weather app relies at some point on data collected by NOAA - National Oceanic and Atmospheric Administration. Your stock app will show the impact of the GDP statistical release from the BEA - Bureau of Economic Analysis. Telecommunications and spectra on these devices will most likely be influenced by NTIA - National Telecommunications and Information Administration. The components in the devices are part of trade as advocated by the ITA - International Trade Administration. The way an app or product is positioned geographically most likely have relied on Census Bureau data. The startups that create software for this device have either directly or indirectly accessed resources from the EDA (Economic Development Administration) or MBDA (Minority Business Development Agency). The majority of the bureaus of the Department of Commerce have had some impact on this one material aspect of your life. And ….. All of that happens before lunch. The Department of Commerce This is why I can candidly say that the Department of Commerce is American’s Data Agency and I can say it confidently knowing that it is not an exaggeration. Literally, the Department collects and disseminates data that extends from the surface of the sun to the deepest depths of the ocean. The simple, yet powerful, mission of the Department is to create the conditions for economic growth and opportunity. Additionally, the Secretary has seen it fit to create a startup of sorts within the Department focused on Data – this is the Chief Data Office. And our mission is three-fold:
Today, I want to tell you about two initiatives that the Office is embarking upon. The first is the New Exporters project.  New Exporters Project I want you to close your eyes for a few seconds and Picture Stephanie – a small business owner – she manufactures furniture. And she does it really, really well. In fact she won awards at her county fair for her rustic designs. She produces about 50 to 100 units of furniture per week out of her wood shop. What if there were a way to provide Stephanie with the necessary market intelligence to enable her to determine where she should sell in order to maximize her revenue stream? Imagine if one day, she receives a personalized recommendation on where to export. A simple card or email could provide the average percent growth in revenue of similar merchants in other parts of the country. If these merchants, who are like Stephanie, can do it, so can she. Commerce data has the potential to unlock that market intelligence for small businesses. And this is the goal of the new exporters project. The second project is the Risk Models 2.0  Risk Models 2.0 Project You get home from a busy day at work. It is June and you are so tired so you park your car in your driveway. You go inside. You play with your kids, eat dinner, tuck them in and wake up to find huge lumps of hail resting in the dents they have created in your car. Wouldn’t it have been more efficient, less annoying and less costly, if your weather app could alert you when there is a high chance of hail and advise you to move your valuables indoors? Maybe, it is your insurance provider that calls you to tell you to take evasive measures because they now have weather models built into their risk models. Wouldn’t it be nice? In both of these cases, one thing is very clear. The power of Open Data, and more specifically Open Data from the Department of Commerce, lies in its integration and application to user-driven scenarios that improve lives and businesses. I am going to end there (as I am standing between you and lunch) and I‘m going to ask you to do one thing. As you are having lunch and making new friends, think to yourself: “How can I help the Department of Commerce to help me?” And send me an email Thanks to Jeff Chen for helping with the framing of this talk.
 I will keep this short; in order not to rant too much. The sole purpose of this post is express my disappointment in things Jamaican. Politicians who do what they decide they want to do - irrespective of the will of the people, irrespective of the damage and chaos that their actions will cause; irrespective of the generational hurdles that they are putting up for the nation's children (their kids are insulated) - is not what we are sold as people who elect "representatives" to advocate for our collective best interest. There is no transparency in this Constitutional Monarchy that Jamaica resides in. Are Jamaicans fully aware of the holdings, affiliations and (business) interests of their elected politicians? Are Jamaicans fully confident that their leaders are doing what is right for them and not what is right for their own concerns? Where is the accountability necessary to ensure that "elected service" is exactly that? Service to the people. Has it all been tainted?  The Root Of It All - Corruption I know you have heard this sankey before - over and over again - beaten to death - to the point where it does not phase you, it does not register, and everyone assumes that it is a part of life. It is should never be a "natural" part of anything. It is a bastardization of the system that the Jamaican public is sold as democratic. Corruption is formally defined as "the use of public office for private gain". I am not just talking about your grand-daddy's corruption here. A bribe here or there to clear a barrel from the wharf. A likkle pocket money to make some government process go faster or smoother. All of these are well-understood and rightly identified as corrupt activities. I am talking about more damaging and long-lasting acts. Things like creating financial avenues that "seemingly" addressing public problems, while profiting from it in the back-end. Things like manipulating financial markets, misinforming the Jamaican people and ensuring that your actions lead to profits for you and yours. I am talking about systemic games that hurt millions of people for very long periods of time, but that are not illuminated and visible to the public (till the worse happens). Can anyone in public office in Jamaica honestly and publicly say that you are not corrupt (by the generally accepted definition above)? Everyone is at fault.  The Jamaican Media The media is supposed to be one of the first countermeasures in our system - holding public officials, who have been entrusted with the keys to the country, accountable. Where is the media on matters that are important to the present and future? Where is the Jamaican media when it comes to investigative journalism? Where is the media when it comes to being the objective arbiters of truth and what is good and right for Jamaicans? Where is the media when it comes to representing the common youth and ensuring that their future will be better? Crickets everywhere. Unless you like sensational, surface-level discussions about the inconsequential. Where is the media when it comes to shining a light on corruption and ensuring that Jamaica lives up to its promise? When did journalism die in Jamaica? When did the media give over its power to the elites and become their lapdogs? When did this critical check-and-balance in the Jamaica governance process become ineffective? Irregardless of the answers, it is time for a resurgence. Time for the media to start fulfilling their extremely important mission. However, there are a lot of parties involved; not just the media.  The Jamaican People Light bills are now taxed. The Road Traffic Act is in full effect. National Housing Trust !!!!!! The Cybercrime Act of 2015 seeks to make all Jamaicans potential criminals for just interacting and expressing themselves online. The wholesale privatization of public Jamaica assets continues full steam ahead. The Jamaican government still prioritizes international loan debt servicing over the needs and growth of its people and the local economy. And what has been the reaction of the public? A few rumblings here today. A few rumblings there tomorrow. Nothing after a week. Back to normal and their voice counts for nothing. A horrible example of representational politics if I ever saw one. The "Noise. Noise. Block Road" strategy has been "best in breed" practice in Jamaica since time immemorial. It has also been wholly useless and ineffective for just as long. How about the people trying different techniques to hold government and media accountable? What about hitting them where it hurts? What about investigating the behind-the-scenes deals that are really driving these initiatives? What about naming and shaming the people involved? What about finding the by-laws and statutes that can empower you to call people (representatives or other) on their bullshit? What about real "grassroot organization" to educate, uplift and empower voters to be accountability barometers for the people they elect? What about trying something different, something new, something unexpected, that the people who have the public trust would never expect? Honestly, I don't know what will work, but I know a few million of us can come together and try a whole heap a ting.  The Jamaican Intelligentsia At this point, I know I have lost a lot of you and that is fine. I know I promised to be short and I think I am failing miserably at that too. Okay. However, two more things before I sign off. The most egregious of all the phenomena in the Jamaican ecosystem to me is the people that know better, but are just complacent and resigned to the status quo. To whom much is given, much is expected. It is through the shared sacrifice and labor of every single Jamaican that the Intelligentsia was and is able to get to where they are, whether they are still in Jamaica or in the diaspora. Sure, you worked hard individually. Sure, you had the love and support of your family. However, if you did not have the infrastructure, name-recognition and prestige that comes from all of us, even the ones you won't publicly embrace and or acknowledge, working together and making Jamaica the international power house that it is, then you would not be where you are today. Let that sink in. Now, think about how your complacency is helping make this ship sink faster. Then think on how you can help fix the problem and do something.  The Effects of Unaccountability: Apathy and Powerlessness I have the luxury of being an observer and an insider at the same time. I am a Jamaican, who like many others, capitalized on education to increase the number of opportunities available. I am forever grateful of my heritage and know that it is my responsibility to give back in whatever means I can (whenever I can) This is why when it comes to matters related to Information Technology and Jamaica, I provide help (if asked for or not). A few days ago, I provided my thoughts on the disastrous impact of the Jamaican Cybercrime Act of 2015 (click here for that post). This advice was unsolicited. I am anti-politics and pro-people. The reaction that I received from the blog post indicated that there is apathy and powerlessness in all segments of Jamaica when it comes to public policy. "This does not apply to me" "There is nothing I can do about it" "The politicians will do whatever they want, no matter what I say" These were sample responses. It broke my heart. If you cannot affect your future, then who can? "If it's to be, It's up to me" - Source Unknown
|
Dr Tyrone Grandison
Executive. Technologist. Change Agent. Computer Scientist. Data Nerd. Privacy and Security Geek. Archives
May 2018
Categories |

 RSS Feed
RSS Feed

|