|
These are exciting times for tech in the Federal government. DJ Patil has joined the administration as the first ever US Chief Data Scientist, Megan Smith looking for more technologists to join the United States Digital Services, and the Presidential Innovation Fellowship program is recruiting for the next round of Fellows. The excitement is both top-down and bottom-up. There are exciting developments on the ground - percolating in the agencies. At a roundtable hosted at the John Kennedy School of Government in Boston, Massachusetts, the participants spent over three hours discussing the current state of the skills economy, its current shortcomings and the actions required to make progress in the field. The job postings of businesses, which want employees, identify the demand in the market. The resumes of job seekers represent the supply side, and the educational institutions that provide training facilitate mechanisms to meet the long-term system needs. Unfortunately, there has been at least two decades of activity in the workforce/skills field that has yielded a fragmented mesh of uninteroperable and disconnected systems and portals. To ensure that the American worker has a fighting chance in this (and the upcoming) century, there has to be several fundamental steps that must be taken; and be used as the bedrock of the industry.  The first step is defining a skill. The individual components of a skill or competency need to be defined and agreed upon.  The second step is articulating (and growing) the set of skill terms. This would enable a common language and reduce the possibility of a 'Tower of Babel' situation. 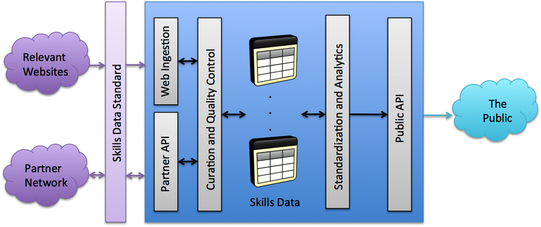 The final step is the creation of a platform that demonstrates the value of an open API (Application Programming Interface) over a set of skills data that covers all aspects of the skills triangle. This platform is a public-private partnership that leverages Federal and business stakeholders.
1 Comment
** Note: The opinions expressed within this post represent only the views of the author and not any person or organization As a Presidential Innovation Fellow, I’ve had the pleasure of working with some of the most brilliant, forward-thinking minds in the workforce. During the past few months, my work has focused more specifically on skills and training arenas,and one thing that struck me is that the skills ecosystem is the entire economy. Its success will lead to a thriving and solid economic base. It’s one thing to make this realization; translating this realization into action is quite another. The problem of understanding the skills space and iterating on it to produce the system that its users‚ i.e. job seekers, employers, colleges, workforce investment boards, etc. —need is a very important one. Related, it’s one that will require the participation of many more people. Before we delve too deeply into this issue, let’s cover a few basics. The de facto source of skills information, both inside and outside the Federal government, is O*NET - the Occupational Information Network. What Is O*NET? O*NET is a data collection program that populates and maintains a current database of the detailed characteristics of workers, occupations, and skills. Currently, O*NET contains information on 974 detailed occupations. This information is gathered from a sample of national surveys of businesses and workers. For each of these 974 occupations, O*NET collects data on 250 occupational descriptors. As you might guess, O*NET is intended to be a definitive source for persistent occupation data — in other words, data on stable occupations that have existed (and will continue to exist) in the medium term. Examples of some such occupations include firefighter, teacher, and lawyer, to name a few. 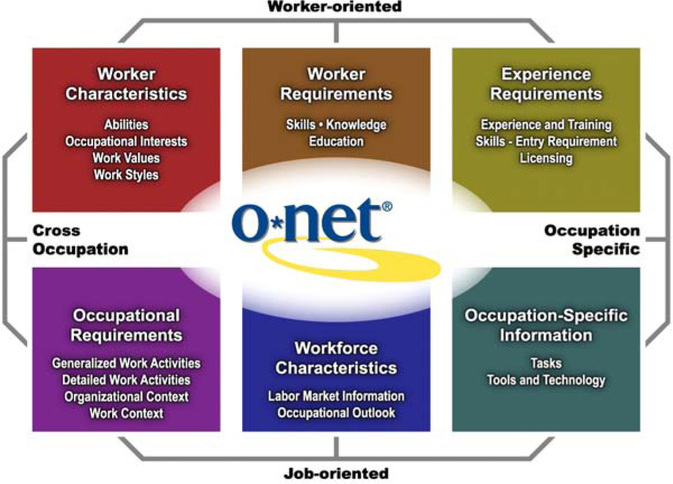 Fig. 1: O*NET Content Model O*NET supersedes the U.S. Department of Labor’s (DOL’s) Dictionary of Occupational Titles (DOT) and provides additional occupational requirements not available in the DOT. The DOT is no longer supported by DOL. O*NET uses an occupational taxonomy, the O*NET-SOC, which is based on the 2010 version of the Standard Occupational Classification (SOC) mandated by Office of Management and Budget (OMB) for use by all federal agencies collecting occupational and labor market information (LMI). What Is O*NET Good At? O*NET is the bedrock of occupational data — some users think of it as a one-stop shop for data on occupations that have existed (and will exist) for some time. In a phrase, it is the gold standard of data on occupational skills – data upon which laws are createdand an economic ecosystem can be built. How Often Does O*NET Data Get Updated? The O*NET data set gets updated once a year. Currently, this is the fastest that comprehensive, consistent, representative, user-centered data, which complies with OMB’s Information Quality Guidelines and data collection requirements, can be gathered and processed. How Does O*NET Collect Its Data Anyway? Data collection operations are conducted by RTI International at its Operations Center in Raleigh, North Carolina, and at its Survey Support Department, also located in Raleigh. O*NET uses a 2-stage sample — first businesses in industries that employ the type of worker are sampled and contacted — then when it is confirmed that they employ those workers and will participate — a random sample of their workers in the occupation receive the O*NET survey form and respond directly. When necessary, this method may be supplemented with a sample selected from additional sources, such as professional and trade association membership lists, resulting in a dual-frame approach. An alternative method, based on sampling from lists of identified occupation experts, is used for occupations for which the primary method is inefficient. This method is reserved for selected occupations, such as those with small employment scattered among many industries and those for which no employment data currently exist on which to base a sample, such as new and emerging occupations. At the current funding level $6.2 million for PY 14 the O*NET grantee updates slightly more than 100 occupations per year with new survey data. Why Use Sampling And Surveys? O*NET currently uses sampling and surveys to gather its massive amounts of data because these are the best techniques that also comply with the OMB Information Quality Guidelines (IQG). These guidelines identify procedures for ensuring and maximizing the quality, objectivity, utility, and integrity of Federal information before that information is distributed. OMB defines objectivity as a measure of whether disseminated information is accurate, reliable, and unbiased. Additionally, this information has to be presented in an accurate, complete manner, and it’s subject to quality control or other review measures. O*NET was designed specifically to address OMB IQG, including OMB information collection request standards, and to correct some fairly serious limitations in the Dictionary of Occupational Titles. What Are Other Foundational Principles of O*NET? In addition to serving as a comprehensive database of occupational data and promoting the integrity of said data, O*NET upholds several other principles. These include the following:
Using survey-based data enables O*NET to have comprehensive coverage, be very representative, enable the data to be validated and cleaned relatively easily, enable the statistical calculation of margin of variance or error, and to meet the OMB data collection requirements. Even though this type of data tends to be higher cost than other data types, survey-based data results in average or mean values (by design). What About Other Types of Data? There are two other primary types of data that could be included in the O*NET data set — transactional data and crowdsourced data. Transactional data tends to be privately owned and have a potential for response bias. Currently, occupational and industry coverage is limited, e.g. in certain industries, online job postings are the norm and in others, it is not. Also, the use of online job postings vary with the size of the firm — smaller employers are less likely to post job openings online. Finally, many postings don’t specify the information desired by O*NET curators. Crowdsourced data tends to the least representative of the set, has the greatest potential for response bias, can be very difficult to validate independently and can easily capture leading or emerging variations. Both transactional and crowdsourced data would require significant investments in curation and management for them to satisfy the OMB Information Quality Guidelines and the O*NET Foundational Principles, which are intended to fix the problems with the DOT. What Is The Biggest Misconception About O*NET? “Why isn’t Python an O*NET Skill?”, “Why is Active Listening an O*NET Skill?”, “Why are O*NET Skills so broad and generic?” Members of the O*NET team hear these and similar questions with relative frequency. The above questions echo one primary misconception about O*NET,, which is O*NET Skills are too general. What many users don’t realize is that O*NET skills — for example, active learning and programming — refer to cross-cutting competencies fundamental to a given occupation. More specific descriptors (such as systems, platforms, and other job-specific tools) are captured under the Tools & Technology section of an occupational profile. O*NET Skills, as perceived by most of the public, are actually a combination of what we describe in the Tools & Technology, Detailed Work Activity, Abilities, Tasks, Skills and Knowledge sections of an O*NET occupational profile. In short, Skills are just the tip of the occupational iceberg. What Are The Issues That You Hear Voiced Most About O*NET? The current set of concerns with the O*NET program include:
Official datasets from the Federal government are constructed to be a stable, steady base upon which more transitional elements can exist. This stability is designed to ensure that the American people see a consistent face when dealing with their government. For this reason, jobs that appear and disappear within the space of months or a few years, like Chief Fun Officer or Growth Hacker, are not immediately included in the O*NET database. Only occupations that have stood the test of time should be included in an authoritative source; upon which regulatory decisions are made. How Do We Solve These Issues? A public-private partnership that produces a Skills Market Platform (SMP) (Fig. 2), which is an open, dynamic, growing, standards-based, public-facing platform for skills data. 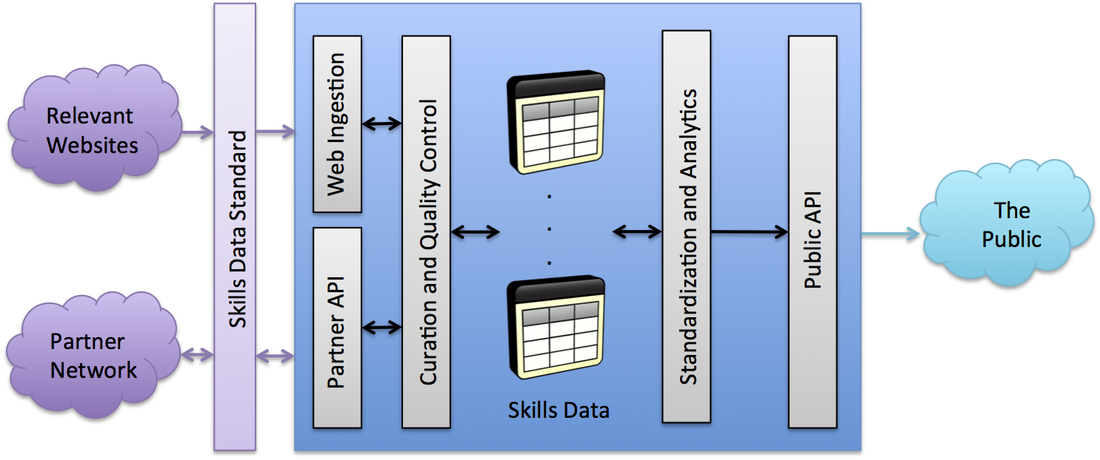 Fig. 2: Reference Architecture for a Skills Market Platform (SMP) The SMP should be run by a nonprofit that will handle the data curation, quality control, analytics and the public application programming interface (API). It is assumed that all contributions to the SMP will be tagged with skills from the Skills Data Standard (SDS) – a standard that is currently being developed. Employers can provide tagged job descriptions. Job seekers can tag their resumes using the SDS taxonomy or import their skills using OpenBadges (or similar) framework. Colleges can tag their courses with the imbued skills. Certification bodies can tag their programs with the delivered skills. The core idea behind the SMP is to conceptualize, design, and build a national skills platform — which would be populated with data over time. Federal government information and existing taxonomies would provide the foundational structure and bring data from O*NET, from the Bureau of Labor Statistics, Commerce data from the Census, the American Community Survey, and the Longitudinal Employer-Household Dynamics data sets. Other partners would be able to upload additional data—such as a college course catalog, or the competencies imparted by a specific certification—or data mined from tagged job postings or resumes. Local areas where community colleges and the workforce system are already collaborating closely with business — such that curriculum is closely tied to employer skills demand could upload information on the linkages between employer skill demand and specific competency-based education modules. Such early adopters would be able to demonstrate the utility of such a platform and build a community to further build out and participate in the SMP. The ultimate goal is for the Federal government to facilitate the creation of the innovation platform for skills; enabling any American to freely and openly leverage a common language and knowledge base. What Needs To Be Done The Skills Market Platform relies on an existing:
Ever wondered what skills a particular certification course gives you? Ever debated the true skills details of a job description? Are you passionate about skills, competencies, abilities and knowledge? Contribute to this effort. Spend some time helping us create the Skills Data Standard. Donate some programming and design cycles to implementing the Skills Network Protocol and or the Skills Innovation Layer. Help change the world as we know it.  The skills market encompasses the entire economy. However, I feel like there are so many people who are not aware of the Federal sources in the skills arena. So, this blog will highlight the primary source from the Federal government, O*NET - The Occupation Information Network. 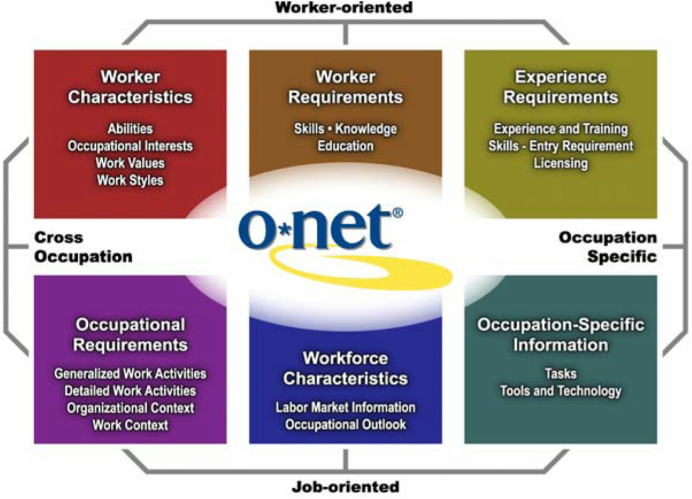 Fig. 1: O*NET Content Model What Is O*NET? O*NET is a (data collection) program that populates and maintains a current database of the detailed characteristics of workers, occupations, and skills. Currently, O*NET contains information on 974 detailed occupations, which are gathered from a sample of national surveys of businesses and workers. For each occupation, O*NET collects data on 250 occupational descriptors. O*NET is intended to be a definitive source for persistent occupation data, i.e. stable occupations that have been (and will continue to be) in existence over the medium term. O*NET superseded the U.S. Department of Labor’s (DOL’s) Dictionary of Occupational Titles (DOT) and provides additional occupational requirements not available in the DOT. The DOT is no longer supported by DOL. O*NET uses an occupational taxonomy, the O*NET-SOC, which is based on the 2010 version of the Standard Occupational Classification (SOC) mandated by Office of Management and Budget (OMB) for use by all federal agencies collecting occupational and labor market information (LMI). O*NET is the bedrock of occupational data. It offers a stable foundation that contains information on jobs and skills that are not fleeting. In a phrase, it is the gold standard of data on occupational skills. Why Use Sampling and Surveys? The primary reason O*NET currently uses sampling and surveys is that these are the best techniques for maximizing the quality, objectivity, utility, and integrity of information prior to dissemination. O*NET uses the OMB Information Quality Guidelines for all Federal statistical information, which defines objectivity as a measure of whether disseminated information is: 1. Accurate 2. Reliable 3. Unbiased 4. Presented/disseminated in an accurate, clear, complete, and unbiased manner 5. Subject to extensive review and or quality control What Are Other Foundational Principles of O*NET? O*NET is designed to be:
Why Does O*NET Only Contain Survey-based Data? Using survey-based data enables O*NET to have comprehensive coverage, be very representative, enable the data to be validated and cleaned relatively easily, enable the statistical calculation of margin of variance or error, and to meet the OMB data collection requirements. What About Other Types of Data? There are two other primary types of data that could be included in the O*NET data set — transactional data and crowdsourced data. Transactional data tends to be privately owned and have a potential for response bias. Currently, occupational and industry coverage is limited, e.g. in certain industries, online job postings are the norm and in others, it is not. Also, the use of online job postings vary with the size of the firm — smaller employers are less likely to post job openings online. Finally, many postings don’t specify the information desired by O*NET curators. Crowdsourced data tends to the least representative of the set, has the greatest potential for response bias, can be very difficult to validate independently and can easily capture leading or emerging variations. Both transactional and crowdsourced data would require significant investments in curation and management for them to satisfy the OMB Information Quality Guidelines and the O*NET Foundational Principles, which are intended to fix the problems with the DOT. How Is O*NET Used? O*NET is the common language and framework that facilitates communication about industry skill needs among business, education, and the workforce investment system. The O*NET data is used to:
The O*NET database and companion O*NET Career Exploration Tools are also used by many private companies and public organizations to tailor applications to their needs and those of their customers. How Do I Access O*NET Data? The O*NET database is provided free of charge to the public through O*NET OnLine. O*NET Data is also available through the My Next Move, and My Next Move for Veterans websites; through the O*NET Web Services application programming interface (API); or by downloading the database, particularly by developers who provide applications targeted to specific communities or audiences. How Does O*NET Collect Its Data? The O*NET data set gets updated once a year. O*NET uses a 2-stage sample — first businesses in industries that employ the type of worker are sampled and contacted — then when it is confirmed that they employ those workers and will participate — a random sample of their workers in the occupation receive the O*NET survey form and respond directly. When necessary, this method may be supplemented with a sample selected from additional sources, such as professional and trade association membership lists, resulting in a dual-frame approach. An alternative method, based on sampling from lists of identified occupation experts, is used for occupations for which the primary method is inefficient. This method is reserved for selected occupations, such as those with small employment scattered among many industries and those for which no employment data currently exist on which to base a sample, such as new and emerging occupations. At its current funding level, O*NET updates slightly more than 100 occupations per year with new survey data. What Are The Survey Response Rates? Currently, more than 144,000 establishments and 182,000 employees have responded to the survey request, resulting in an establishment response rate of 76% and an employee response rate of 65%, which compare favorably to other establishment surveys. O*NET Usage Statistics Current O*NET Usage Statistics During 2014, the O*NET websites (O*NET OnLine, My Next Move, My Next Move for Veterans, Mi Proximo Paso) averaged over 4 million visits per month. Fig. 2 shows the total site visits by year from 2002 to 2013. 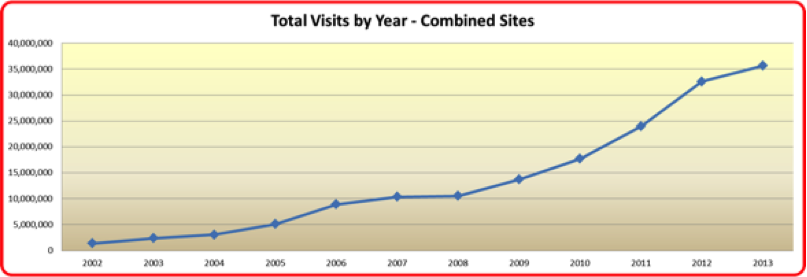 Fig. 2: Total Site Visits for O*NET web properties There is some pattern of seasonality that appears to follow the school calendar. Peak months with over 5 million visits in 2014 were: April, September, and October. The O*NET database has been downloaded 83,573 times from 2002 to 2014. Fig. 3 shows the database downloads in each year. 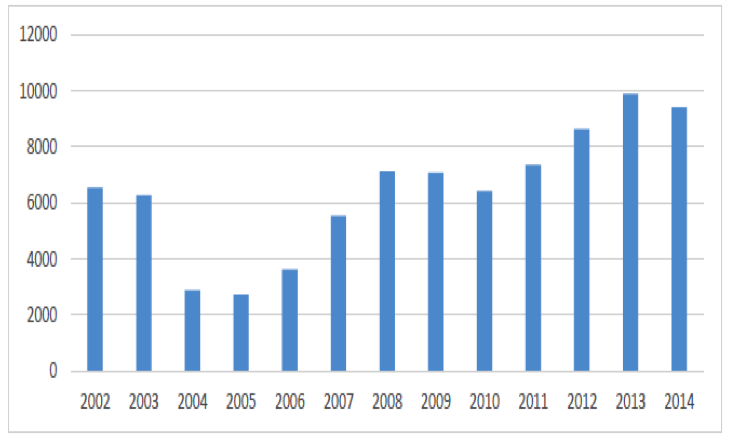 Fig. 3: O*NET Database Downloads, 2002 - 2014 O*NET Web Services and APIs were introduced in 2012 and their usage is steadily increasing through 2014. At the close of 2014, there were 343 total registrants for O*NET Web Services. Fig. 4 shows the progress since 2012. 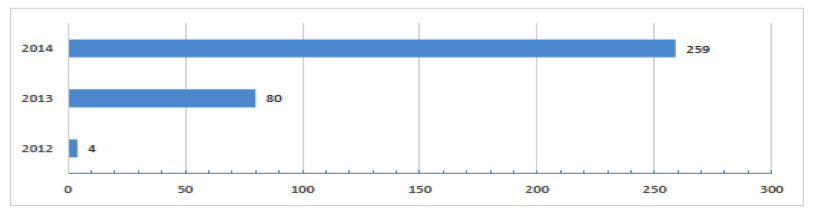 Fig. 4: O*NET Web Services Registrants, 2012 - 2014 The breakdown of the users of O*NET Web Services is detailed in Fig 5. 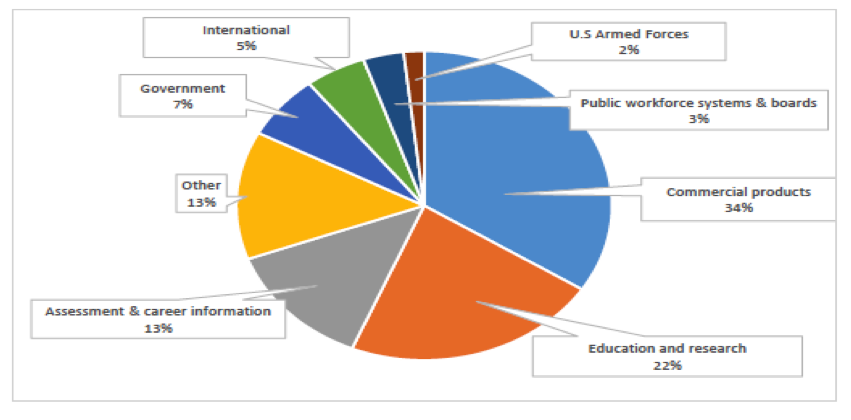 Fig. 5: Registrant Composition for O*NET Web Services Without the help of the O*NET team, this would not be possible. Thank you. A lot of the content comes from a factsheet that the team worked on.
 This blog post is not about what you think it is about; and yet it is precisely what you think it is about. Let me explain. A few days ago, I was reading an article, which was originally published on October 3rd, 2014, entitled "The White Problem". The author is Quinn Norton, who is a white journalist that covers hackers, bodies, technologies and the Internet. Firstly, her post and her part 2, "How White People Got Made", should be required reading for all Americans. Secondly, it raised several important points that most students of the humanities, and the history of peoples' interactions over the centuries, would appreciate and easily identify as artificial constructs erected in an effort to oppress and maintain privilege, which was and is the dominant driving force. For more context, read one of my all-time favorite books - "Pedagogy of the Oppressed". Tucked away in Quinn's paragraph was a sentence, which seemed to be nonchalantly included and inconspicuously placed, that caught my eye and that perfectly represents the state of the computing industry today: "Whites spent hundreds of years excluding others from resources, often by violence, and claiming ownership over wealth created by those same non-whites."  At the highest conceptual level, replace Whites with Tech Company Owners and you get a glimpse of what I saw. The last wave of uber-successful technology companies have two things in common:
A consequence of the second point is that content generators make pennies on their content; while content distributors and everyone else higher in the supply chain make orders of magnitudes more money. It is standard practice for the current (and emerging) set of tech companies to write into either Terms Of Use Agreement, Privacy Policy, End User License Agreement or other user agreement document that information supplied or generated by the user is property of the company and can be viewed as their asset that they can use to serve their purposes. The ultimate purpose is making a profit for the business owners. Their user base do not see any compensation from the use of their data. To selectively quote Quinn, "Whites spent ..... years excluding others from resources, often by violence, and claiming ownership over wealth created by those same non-whites." The violence component enters the picture when you think of the strategies that these companies employ to either attain or maintain their positions of dominance. This includes wage suppression of their employee pool, corporate espionage of their competitors, subverting the market protections and creating barriers to entry and growth through legislative and other means, etc. If the current American premise, only supported by the Citizens United ruling, is to be believed that corporations are people too, then all of the acts mentioned above would constitute violent, aggressive acts against real and corporate beings. If you don't believe that corporations are people, then the above behavior is simply immoral, callous and selfish on the part of the titans of corporate America and a direct jab at everyone else in society. Proponents may mention that this is all just good business and it is simply how the free market works. The Free Market is a product of everyone in it. It is dynamic. It is not something that is external and uncontrollable (or rather un-influence-able). We all help define, create and evolve the free market and the rules that acceptable or not. Thus, behavior in the sole interest of maximizing profit for your shareholders (and ignoring the potential severely negative consequences of one's actions) is not an unchangeable law of nature. It is yet another tool used by "whites" to wrestle control of resources from everyone else. All of this is further complicated when you examine the makeup of the company owner base and the user base. The company owner base has a high percentage of white men. The user base has a high percentage of minorities. The employee mix of these companies is predominantly white and Asian males - an issue that has been written about enough elsewhere [See Silicon Valley's Diversity Problem and How Diverse is Silicon Valley]. I leave the rest for you to ponder.  "It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair, we had everything before us, we had nothing before us, we were all going direct to Heaven, we were all going direct the other way - in short, the period was so far like the present period, that some of its noisiest authorities insisted on its being received, for good or for evil, in the superlative degree of comparison only."
- A Tale of Two Cities (1859), Charles Dickens.  The article by Jules Polonetsky (Executive Director, Future of Privacy Forum) on "Advice to White House on Big Data", which was published today (April 1st, 2014) , brought home an important point to me. The right conversation is not being had. A honest discussion is not taking place about the difficulty of the issues to be addressed with regards to Big Data Privacy. When leaders and policy makers, who are not technical experts in the space, are provided with guidance that obfuscates the real issues, it will not lead to situations that are good for the general public. Thus, I feel compelled to speak up. The segment of Jules' article that forced me to comment was "While the Federal Trade Commission (FTC) has acknowledged that data that is effectively de-identified poses no significant privacy risk, there remains considerable debate over what effective de-identification requires." There is so much nuanced truth and falsity in that statement. It makes me wonder why it was specifically phrased that way. Why lead with the FTC's assertion? Why not simply state the truth? Is it more important to be polite and show deferrence than it is to have a honest conversation? The current chief technologist of the FTC, Latanya Sweeney, demonstrated over a decade ago that re-identification of de-identified data sets was possible with around 80+ percentage of supposedly safe/de-identified data (read more). This is a fact that I am highly confident that most of members of the Future of Privacy Forum are well aware of. So, why lead with a statement with limited to no validity? This confusion lead me to my comment on the article. However, let me re-state it here and provide a bit more detail. What is De-Identification? Simply put, de-identification is the process of stripping identifying information from a data collection. ALL the current techniques to enable de-identification leverage the same basic principle - how can one hide an arbitrary individual (in the data set) in a (much larger) crowd of data, such that it is difficult to re-identify that individual. This is the foundation of the two most popular techniques k-anonymity (and it various improvements) use generalization and suppression techniques to make multiple data descriptors have similar values. Differential privacy (and its enhancements) add noise to the results of a data mining request made by an interested party. The Problem At this point, you are probably saying to yourself "This sounds good so far. What is your problem, Tyrone?" The problem is that the fundamental assumption upon which de-identification algorithms are built on is that you can separate the world into a set of distinct groups: private and not-private*. Once you have done this categorization, then you easily apply a clever algorithm to the data and then you are safe. Viola, there is nothing to worry about. Unfortunately, this produces a false sense of safety/privacy, because you are not really safe from risk. Go to Google Scholar and search on any of these terms: "Re-identification risk", "De-identification", "Re-Identification". Read Nate Anderson's article from 2009 - “Anonymized” data really isn’t—and here’s why not. Even better, get Ross Anderson's slides on "Why Anonymity Fails?" from his talk at the Open Data Institute on April 4th, 2014. In Big Data sets (and in general data sets), the attributes/descriptors that are private change depending on the surrounding context. Thus, things that were thought to be not-private today, may become private a second after midnight when you receive new information or context. For Big Data sets (assuming you are merging information from multiple sources), there is no de-identification algorithm that will do anything more than provide people with a warm and fuzzy feeling that "we did something". There is no real protection. Let's have a honest discussion about the topic for once. De-identification as a means of offering protection, especially in the context of Big Data, is a myth. I would love to hear about the practical de-identification techniques/algorithms that the Future of Privacy Forum recommends that will provide a measurably strong level of privacy. I am kind of happy that this article was published (assuming it is not an Aprils' Fool Joke) because it provides us with the opportunity to engage in a frank discourse about de-identification. Hopefully. *I am stating the world in the simplest terms possible; for the general audience. No need to post any comments or send hate mail about quasi-identifiers and or other sub-categories of data types in the not-private category.
NB. You will also notice that I have not brought up the utility of de-identified data sets, which is still a thorny subject for computer science researchers.  It occurred to me this morning, while going through my news feeds, that it may not be obvious to everyone why companies do not (and are hesitant) to protect customer data. The "Really?" moment came while I was reading "Customer Data Requires Full Data Protection" by Christopher Burgess. I took it as a given that most people knew intuitively why enterprises choose not to protect customer data; as they do their intellectual property. It never occurred to me that it was a mystery to the general public or that it was up for discussion or even an issue worthy of thought cycles by the industry punditry. This leads me to the obvious. Risk Customer data is their asset with the lowest risk profile. Even though it is necessary to help with the successful management of the customer relationship and for some businesses it is the driving force behind their value (or valuation), the impact of compromise (or damage) of that data has (relatively) little impact on the company itself. In legal terms, "harm" is done primarily to the data owner ("customer"), not the data steward ("company"). For example, each of the hundreds of millions of people affected by the Target breach face a lifetime of vigilance over their financial identity and activity. The possible harm is significant and the total impact on the data owners could reach the order of hundreds of billions of dollars. The possible harm for Target will be capped by legislative action and will be a (small) fraction of the company's profit margin. Over the long term, Target can weather this storm and still be a viable company - making this an acceptable risk. However, for their customers, this is potentially a life-altering event from which they cannot recover. The Expense of Data In most cases, customer data is either donated by the customer or gathered by the company's customer relationship managers. Compared to acquiring patents to protect the firm's business processes or generating information on optimizing their internal operations, the price and cost of customer data is negligible. Cost- Benefit Tradeoff of Protection Though the benefits of protecting data are well-established and the current trend of multiple daily attacks is not dissipating, the discipline of data protection is a risk management process (and rightly so). Protection technology is expensive to implement and incorporate into an existing business, has an (often negative) impact on the internal operations of the business (i.e. it impacts how you perform your core functions, it impacts the performance of those functions, it impacts the requirements needed to execute these functions) and is viewed primarily as a cost center (with no real, measurable return on investment at the time of installation). Thus, data protection is a defensive investment with perceived value only after security and privacy incidents have been thwarted. So, companies choose to deploy data protection technologies for the data that are of the highest value to them. You put these factors together and you get our current state of affairs, where "cheap", "low-risk" (to them) customer data is often left unprotected because the benefit of doing so is not worth the cost of doing so. It becomes an acceptable (and tolerable) business risk that they can rationally take. Unfortunately, I believe this perspective is flawed and will do more harm than good in the long term. The first step in solving this issue is to have companies realize that the damage done when customer data is compromised will have significant impact on their current and future profitability. In this environment, Security and Privacy are competitive differentiators; at least until all companies are on the same page. Invitation to Join Mozilla Reception for San Francisco Premiere of "Terms and Conditions May Apply"7/30/2013  What follows below is an invite from the privacy team at Mozilla:
Terms and Conditions May Apply is a new documentary about Internet privacy with impeccable timing. The film is in select theaters across the country starting July 12th and will serve as the launchpad for a social action campaign (to be housed at trackoff.us) that will demonstrate public demand for stronger privacy protections, including baseline privacy standards. Last week the film was deemed a NYT Critics' Pick. About the film: Terms and Conditions May Apply exposes what corporations and the government are learning about you with every website you visit, phone call you make, or app you download, with stories of surveillance so unbelievable they're almost funny. As privacy and civil liberties are eroded with every click, this timely documentary leaves you wondering: if your private information is for sale to the highest bidder, who's doing the bidding? In San Francisco, the film premieres at The Victoria Theatre on August 2nd at 7:15pm. Following the film will be a Q&A with the director, Cullen Hoback, and issue experts, including Harvey Anderson, Mozilla's SVP of Business and Legal Affairs and a representative of the ACLU Northern California. Mozilla would like to invite you to attend a pre-screening reception from 4:30-6:30pm at our San Francisco office. We will be serving light appetizers and beverages, showing some film clips (including the 2012 privacy-related Firefox Flicks winners), and discussing Internet privacy. Please RSVP for the Mozilla reception by end of day on Wednesday. See wiki.mozilla.org/SF for more info on our location. Our office is located in the former Gordon Biersch Brewery space on the Embarcadero and is convenient to BART, CalTrain, Muni, and ferry. 
There are quite a few things that should be of concern for the average Internet user - your computer can do things that will cause you harm, someone can spy on your Internet traffic, one of your service providers can either sell your data or hand it over to the authorities; without your consent, knowledge, or even compensating you.
Additionally, there is the risk of an arbitrary website owner collecting and looking through your Web surfing behavior. Unfortunately, all of these situations happen a few million times every second. Not knowing that these things are happening is the enabling factor for a trillion dollar industry. Ultimately, you should be uneasy with the possibility of having your identity stolen or being disqualified from opportunities, based on secretly collected data. (excerpt from "Practical Privacy Protection Online For Free". Buy your Copy now)  I have been thinking lately about what it takes to have corporations start seriously thinking about data ownership from the point of view of the people who provide the information.
What would it take for an entity, whose business model mainly depends on the self-proclaimed rule - "we store your data, so we own your data", to give up some control (and revenue)? The idea that the owners of the "means of production" would claim that they own "all raw material given to them" is ridiculous in any other field. However, it is acceptable in the IT industry - a discussion I will have in another blog. Back to the main thought - How to get businesses to play fair with the people who give them data? Last week, Gartner hinted to the possible answer and our possible future. In their special report examining the trends in security and risk, Gartner predicted that 90 percent of organizations will have personal data in IT systems they don't own or control. This prediction hints to a future where corporations are losing money and control of their revenue stream - data. It is only a matter of time before corporations figure out that when they provide data to other companies that provide a service to them, the service provider should share the revenue they get from using the gifting company's data. So, I am optimistic that corporations will see the value of creating a data ownership ecosystem - as a matter of self-interest and survival. I am sure they will market it as being for the benefit of the regular Web user. However, I am less hopeful that the claimed benefit of this ecosystem (and revised viewpoints on data ownership) will actually see the pocket of the ordinary Web user. Source: ACLU. Voices: Jason Stiles and Melissa Schwartz I like to include the ACLU's 2003 video about "ordering pizza in the future" in most of my presentations about privacy. From the first time I saw it, there were two points that stuck out to me. The first being the power of integrating silos of information to gain insight in customer needs and preferences. In a positive case, you can image a retailer knowing that you will be going on vacation in a week and that you have bought designer clothing in the past being able to highlight deals and discounts on fine clothing for tropical climates. However, as the video points out, every technology (or intention) has positive and negative sides. The line between social good or convenience ("positive") and creepy ("negative") is not well-defined, but is intuitively known by the consumer. The second point is the decreasing levels of privacy inherent when one integrates more and more data (even if one is "only" merging metadata). In the process of collecting more information about someone, it becomes more likely than one can identify that particular person in the large crowd. The collected attributes that describe them and their behavior form a unique fingerprint, which is evident even when portions of the data are de-identified. It is the second point that concerns me most. The current push is towards big data analytics and using cloud technologies whenever possible. This focus puts a spotlight on the erosion of privacy. Unfortunately, there is more emphasis in the mainstream discussion on the potential benefits of this information explosion and very little practical technical or policy action on guarding against the possible negative outcomes. To quote Bruce Schneier, "Data is the Pollution of the Information Age". Shall we wait, like the previous generation, until it is too late to address the problem? |
Dr Tyrone Grandison
Executive. Technologist. Change Agent. Computer Scientist. Data Nerd. Privacy and Security Geek. Archives
May 2018
Categories |




 RSS Feed
RSS Feed

|